
A Content Delivery Network, can be described as a set of servers, distributed globally, with the purpose of providing content to users in an optimized way and in the shortest possible time.
The CDN servers are distributed in several locations, some of these servers tend to be located closer to the destination user than the origin server, which makes the distance that the data travel (physically) is smaller, consequently, delivered more fast.
What can be distributed and stored
The main objective is to store static content, that is, all content that, once generated, is no longer altered. Examples of this content, when we talk about a website, for example, are HTML, CSS, images and JavaScript files.
Although some files are exemplified above, other formats can be distributed without major limitations, such as videos, PDF, TXT, etc.
Content distribution and replication
Due to the distributed nature of a CDN, the content to be provided by it needs to be available to all instances of that network and, basically, there are two ways to carry out the distribution of this content. They are known as PULL and PUSH where the main differences between them is in the way data is made available on the CDN.
PULL Model
In this model, whenever content is requested by the user, the CDN checks if it already has the content on its servers, if not, it makes a request to the origin server, stores the data in its network (cache) and then returns the data to the user. requested.
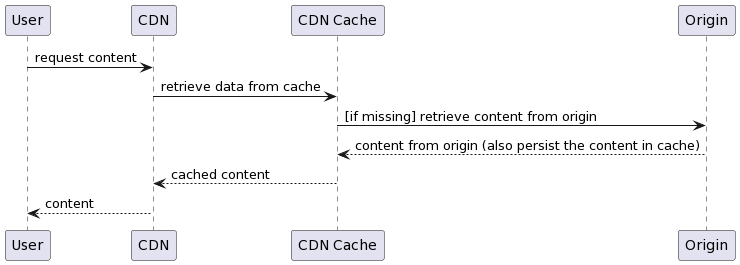 CDN example (PULL model)
CDN example (PULL model)
The main advantage of this model lies in its low implementation complexity, as it is not necessary to make the content to be provided by the CDN available before the user’s first request, as it will be responsible for retrieving this content as needed, that is, as requested. by users. On the other hand, as the content will not be present on the CDN servers during the first requests, they will have a longer response time, given the need to recover this content from the origin servers.
PUSH Model
Unlike the PULL model, here the content to be made available must be available on the CDN servers before the requests are made, that is, the CDN will not be responsible for retrieving the content from an origin, but the developer or application must store these contents manually or by automated processes.
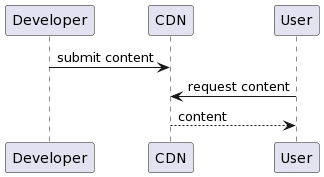 CDN example (PUSH model)
CDN example (PUSH model)
In this model, we have a greater complexity in its implementation, since the content needs to be submitted to the CDN servers in advance, either by automated or manual processes. The automation of these processes can be quite complex and different processes are required for each existing application, which can make automation an extremely complex and costly process. When performed manually, human errors can occur, such as, for example, forgetting to submit some important content, causing an unexpected failure in the execution of the application.
On the other hand, one of the biggest benefits obtained in this model is the consistency of the response, given that the CDN never needs to retrieve data from anywhere other than its own servers, the response time tends to be consistent and low.
Another advantage in this mode is the ability to make systems available without the need for a server, using only the CDN. For example, it is possible to build and provide a website that does not depend on external services, just making the HTML, CSS and JavaScript files available on the CDN, without any need for dedicated servers.
Conclusion
In general, despite adding a certain level of complexity to applications, its use is normally valid and recommended, since, given the proximity of a CDN provider’s servers to the users of its application, the data requested by them are normally delivered with low time, regardless of your geographic location, without the need to add your application servers around the world, allowing you to scale your application/service without necessarily increasing the operational cost.
It is important to say that the purpose of the text was to describe what a CDN is and not detail specific services from specific providers, such as, for example, AWS, which allows dynamic content to be made available. Each provider tends to have different characteristics, either by providing new features, such as geographic availability, and it is always advisable to identify them and validate the one that best suits your needs.
I’ll stop here, thanks for reading, if you have questions or even find errors in the text, feel free to contact me / let me know.


